Go Back
Data Warehouse for VC 101
Table of Content
Data Warehouse 101 for Venture Capital
Every VC firm has data. CRM records, a company or people data source like Harmonic or PitchBook, email threads, meeting notes in Notion, deal memos in Google Docs, pitch decks in Dropbox. What almost none of them have is a way to actually use all of it at once.
The question we hear most often from firms exploring this is some version of: "Why do we need a warehouse if we can just connect our CRM, Harmonic, and Granola directly to Claude?" It's a fair question. Both setups give you answers. Only one gives you answers you can trust.
This guide breaks down what a data warehouse is, why it matters for investment firms in 2026, and how to know if you need one.
The Data Challenge
A typical VC firm runs on 8 to 15 different tools. Attio or Affinity for deal tracking. Notion for internal docs. Gmail and Outlook for email. Google Calendar for meetings. Granola for meeting notes. PitchBook or Harmonic for market data. Slack or Teams for internal comms. Maybe a shared drive or SharePoint for decks and memos.
None of these systems talk to each other natively. The result is four concrete problems that every growing firm eventually hits.
Scattered data
Information about a single company lives in five or six places simultaneously. The CRM has the deal stage. Email has the founder relationship. Notion has the investment memo. PitchBook has the financials. Your associate's personal notes have the real context from that dinner. No single system has the complete picture, and nobody has time to manually stitch it together before every meeting.
The same company, founder, or contact often appears differently across Harmonic, Affinity, PitchBook, email, meeting notes, and spreadsheets. Without a unified layer, duplicate records accumulate, relationship paths are missed, and trust in the system erodes. We've seen firms describe their data as "50 to 75% right", and the painful part is that every manual fix in one system creates a new inconsistency somewhere else.
Context switching kills speed
Before a partner call, someone on the team spends 20 to 45 minutes pulling context from different systems. Before an LP meeting, it's hours of manual data aggregation. Every context switch (CRM to email to Notion to Slack) introduces friction and drops threads. The firms that move fastest on deals aren't necessarily smarter. They just get to the relevant information faster.
No institutional memory
When a senior associate leaves, their deal context leaves with them. The reason you passed on that company three years ago, gone. The warm intro path to that founder, forgotten. The pattern they noticed across the last ten B2B infrastructure deals, lost. Firms confuse having data with having memory. Data is what you've accumulated. Memory is what you can actually recall, reason about, and act on as a team.
Slower decision speed
When an LP requests data, it shouldn't take a week. When a promising founder reaches out cold, figuring out who in your network knows them shouldn't require a round of Slack messages. But for most firms, these are multi-hour or multi-day exercises. That's not a people problem. It's an infrastructure problem.
What Is a Data Warehouse
A data warehouse is a centralized system that pulls data from all your different tools, cleans and organizes it, and stores it in one place so you can query, analyze, and build workflows on top of it.
Think of it as the difference between a filing cabinet per department and a single, searchable library. Each tool you use (CRM, email, calendar, market data provider) keeps generating information. A data warehouse collects all of it, deduplicates it, links it together, and makes it queryable from a single layer.
One practical distinction worth understanding: a data warehouse lets you land data as-is and model it later as needs emerge. You don't need to think through perfect schemas and data structures before you start loading. This is a meaningful difference from a traditional database, where you'd need to design the data model upfront, which adds friction without much payoff when you're still figuring out what questions you'll want to ask. The warehouse approach lets you get started, then shape the data as use cases become clear.
In practice for a VC firm, this means every company, every person, every interaction, every signal from external sources, all connected to a single canonical record. When you look up a company, you see everything your firm has ever known about it in one place: when you first encountered them, every email exchange, every meeting, every internal note, every external data point.
The simplest way to think about it: a data warehouse turns your firm's scattered data into institutional memory, something the whole team can search, query, and build on, regardless of who originally created the information or what tool they used.
What a Warehouse Is and Isn't
A warehouse is: a centralized storage and query layer for data from multiple sources; the foundation that your CRM, dashboards, and automations build on; a system that gets more valuable over time as historical data accumulates; infrastructure that makes your existing tools work better together.
A warehouse is not: a CRM (it sits beneath your CRM and feeds it better data); a dashboard (dashboards are outputs that read from the warehouse); an AI tool (AI is a capability you layer on top of warehouse data); a one-time project (it's a continuously improving capability).
A common misconception: firms often think they need "a dashboard" or "an AI tool" when what they actually need is the data infrastructure that makes dashboards accurate and AI useful. Putting a dashboard on top of messy, disconnected data just gives you a prettier version of the same confusion.
Why Now: People Tolerate Bad Data, Agents Can't
Until recently, the case for a warehouse was about saving analyst time, faster reporting, and cleaner LP communications. All still true. But the real shift in 2026 is what's reading the data.
Here's what happens when a firm tries to skip the warehouse and just connect everything to an LLM directly. Affinity says 10 touchpoints with the founder. Gmail says 5. Harmonic has the round at $12M. Your meeting notes say $15M post. The same company shows up as "Acme", "Acme Labs", and "Acme Inc" across three systems. The model reads all of it. It cannot tell you which version is true.
A partner can look at three conflicting numbers and figure out which one is right. They use context. They know the deal. They know the team. They remember that the $12M figure was pre-revision, that "Acme Labs" is the legal entity, that the 10 touchpoints in Affinity include the founder's accountant. An agent doesn't have that. It picks one. And acts on it.
The data isn't being read by people anymore. It's being read by agents triaging deal flow overnight. Drafting the Monday memo. Flagging portfolio companies untouched in 90 days. People can work around messy data. Agents can't.
This is the new framing. The question stops being "how do we connect more sources" and becomes "what makes the answers trustworthy when no one's checking them." Connecting sources gives you access. A warehouse gives you a more data-driven fund that can be operated by agents.
Every firm will want AI-powered workflows in the next two to three years. AI without structured, clean underlying data is just a chatbot. The warehouse is what makes AI actually useful for investment work, and what makes it safe to delegate work to it.
The Single Source of Truth
The core concept behind a data warehouse is deceptively simple: there should be exactly one canonical record for every entity your firm cares about. Every company, every person, every fund, every relationship.
Right now, most firms have the same company appearing differently across multiple systems. The CRM says "Acme AI" with a Series A close date of March 2024. PitchBook says "Acme Artificial Intelligence Inc." with a different date. The deal memo on Google Drive references "the Acme deal" with details that don't match either. An associate's Notion page has notes from a call that aren't linked to any of these.
A single source of truth means all of these resolve to one record. Every system that needs to reference this company reads from the same canonical version. When something changes (new funding round, a pivot, a leadership change) it's updated once and reflected everywhere.
This sounds obvious. In practice, it's the hardest part of the entire project. It requires decisions: whose data wins when sources conflict? How do you handle companies that pivot or merge? What's the minimum threshold for a record to exist? These are organizational decisions, not technical ones, and they need to be made before any code gets written.
Entity resolution: the engine underneath
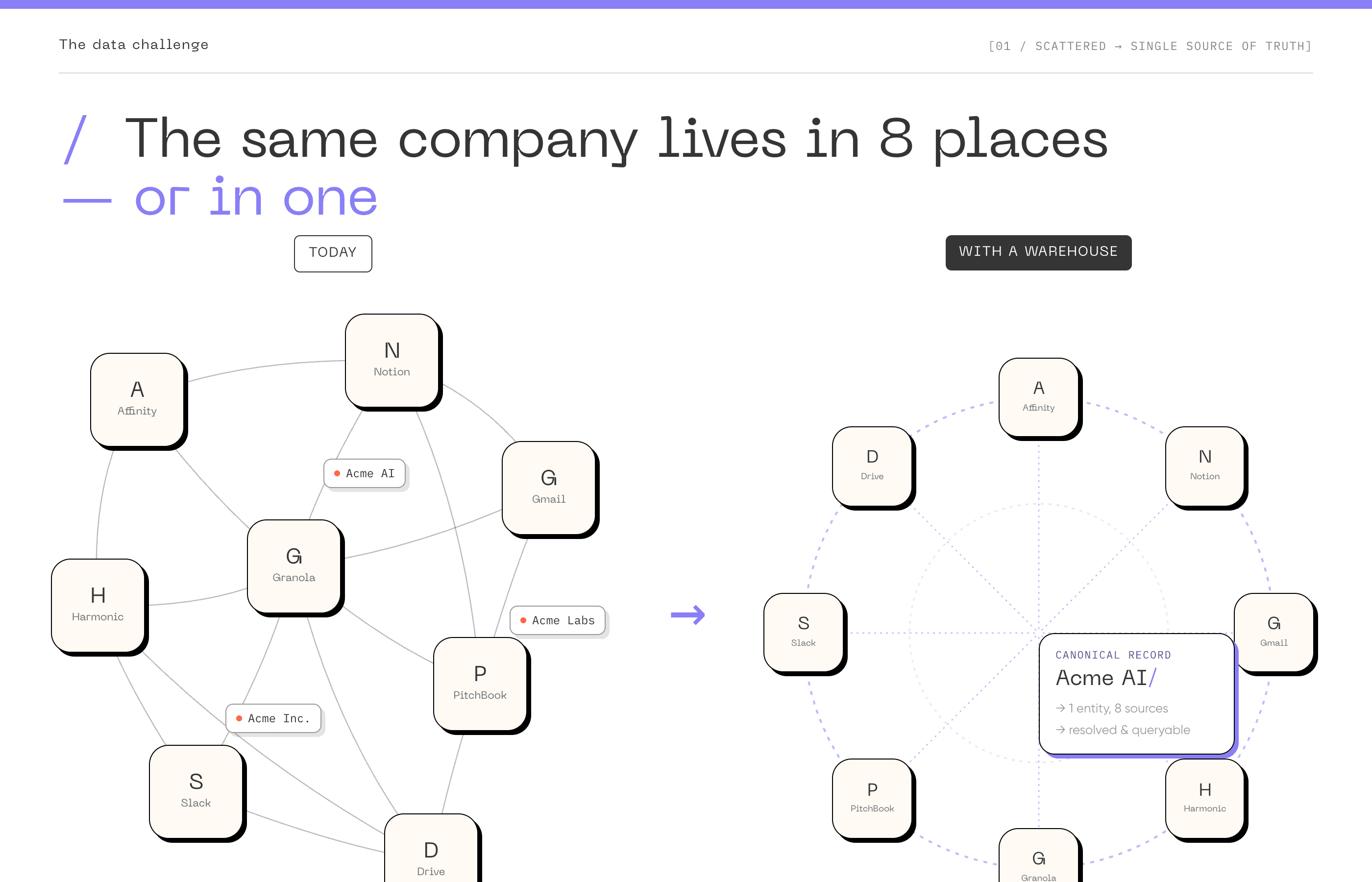
Entity resolution is the technical process that makes the single source of truth possible. It's the logic that determines which records across different systems refer to the same real-world entity. "Acme AI", "AcmeAI Inc.", "acme.ai", and "the Acme deal" all need to resolve to one canonical record. For companies, this involves matching on domains, names, identifiers, and contextual signals. For people, it's harder. Email addresses change, people move between companies, LinkedIn profiles get updated.
Once you know two records refer to the same company, a second problem appears: which source wins for which field. Your CRM has a funding number. PitchBook has a different one. Harmonic has a third. None of them are wrong, exactly. They were captured at different times, by different processes, with different definitions. The warehouse is where you make those decisions explicit and consistent. Funding history comes from PitchBook. Headcount and hiring velocity come from Harmonic. Meeting context comes from Granola. Deal stage and pass reasons come from the CRM.
When PitchBook and Harmonic disagree on a round, PitchBook wins. When the CRM and Granola disagree on what was discussed, Granola wins. These are encoded as rules, not as instincts in a partner's head. This is the part that most teams try to handle at the prompt level first, by telling Claude something like "use PitchBook for funding and Harmonic for headcount". It works for one query at a time. It breaks the moment a workflow has to chain decisions, reason across history, or run unattended. The right place for this logic is in the warehouse's intermediate layer, where it's defined once and inherited by every dashboard, skill, and agent that reads from it.
Getting both pieces right (entity matching and source precedence) is the difference between a warehouse that compounds in value and one that becomes an increasingly confusing mirror of your original data chaos. Neither is a one-time exercise. New edge cases emerge continuously, and the resolution logic needs to evolve with them.
How a Warehouse Is Built
The modern approach is ELT (Extract, Load, Transform) using dbt. Traditional ETL transforms data before loading it. ELT loads raw data first, then transforms it using SQL inside the warehouse. This is simpler because all transformation logic is in SQL, version-controlled, and tested like application code.
How it works in practice: extract data from sources (CRM, PitchBook, LinkedIn, Gmail, Slack) and load it raw into your warehouse using tools like Fivetran or Airbyte. Write dbt models (SELECT statements) to transform raw data: clean and normalize, combine sources, calculate metrics, build final tables for analysis. dbt handles orchestration, testing, and documentation automatically.
The flow: Sources (CRM, Harmonic, PitchBook, Email, Meeting Notes, Slack) -> Extract & Load (Fivetran, Airbyte) -> Warehouse layers (Raw -> Staging -> Intermediate -> Marts) -> Consumers (CRM, Dashboards, Ad-hoc SQL, MCP Servers, Agents).
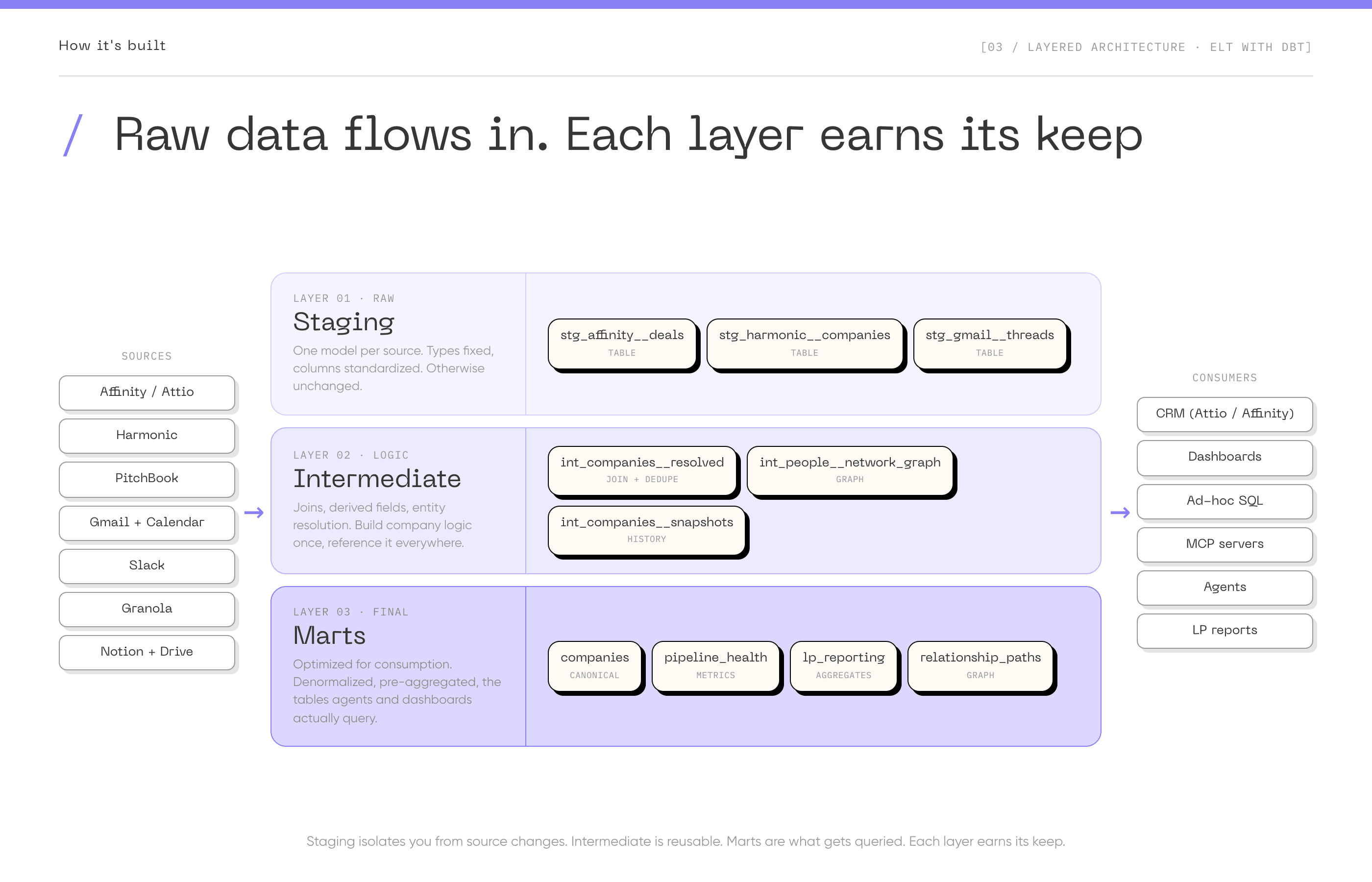
The layered structure
The standard pattern organizes the warehouse into layers. Staging holds raw data from sources, lightly cleaned (data types fixed, column names standardized, but otherwise unchanged). One staging model per source table. Intermediate holds business logic and transformations: joins, derived fields, entity resolution. Marts are the final tables optimized for specific use cases, the ones that dashboards, analyses, and agents actually query.
Why this structure matters: staging isolates you from source changes (if PitchBook changes their schema, you fix the staging model, not every downstream model). Intermediate models are reusable (build company funding logic once, reference it everywhere). Marts are optimized for consumption (denormalized, pre-aggregated, easy to query).
Capture history from day one
One thing easy to underweight at the start: even if you're not running sophisticated analyses yet, capture history. If you're only storing current state (the latest CRM snapshot), you lose the ability to analyze how things changed over time. Daily snapshots oour CRM let you reconstruct what your pipeline looked like at any point. Six months from now, when a GP asks "how many companies did we talk to in Q3 and what happened to them?", you'll either have the data or you won't.
What It's For: Practical Applications
The outputs that matter most aren't just flashy dashboards. They're operational improvements that compound quietly over time.
- Ask anything about your fund, and get an answer you can trust. A GP types: "Show me every fintech company we've met with in the last 18 months that has since raised a Series A, ranked by who in our network knows the founder best." Without a warehouse, that's a multi-day exercise across Affinity, Harmonic, email, and Slack. With one, it's an answer in seconds, sourced from canonical data.
- Pre-meeting intelligence. Before any partner meeting, the system automatically assembles everything your firm knows about the company and founder. First encounter, every interaction since, who else on the team has talked to them, what you thought at each stage, how their trajectory has evolved, who in your network knows them. Not a summary written by an overworked associate the night before. A live assembly from the canonical record, surfaced into the calendar event, ready when the partner walks in.
- Trajectory intelligence. This is the category most CRMs literally cannot do, because they store current state, not history. A company at $2M ARR growing 15% month-over-month is a very different bet than one at $2M ARR that was at $3M eighteen months ago. With snapshots, you can ask: "Which companies in our pipeline have accelerated headcount in the last 90 days?" "Which portfolio companies have slowed hiring after the last round?" Momentum, deceleration, and inflection points become observable instead of anecdotal.
- Pattern recognition on your own decisions. Every fund passes on companies that go on to do well. With memos, notes, pass reasons, and outcomes in one queryable place, the system can surface patterns. "You've passed on three developer-tools companies at seed citing 'crowded market' in the last two years. Two of them raised Series B within 18 months." This is only possible when decisions and outcomes live in the same layer.
- Agent-operated workflows. The newest and most consequential category. Agents that triage inbound deal flow overnight, prioritized by your active theses. Agents that draft the Monday partner meeting memo from the week's pipeline activity. Agents that flag portfolio companies untouched in 90 days. Agents that score new founders against your network and surface the warmest intro path. None of these work reliably without clean data underneath. All of them become possible once it exists.
- Relationship intelligence on the actual graph. When a new company enters the funnel, the system surfaces who in your network has actually interacted with the founders, derived from real email and meeting data. Not who has their LinkedIn contact, but who exchanged substantive messages or had real conversations. This turns a round of Slack messages into an instant lookup.
- Targeted signal routing. Instead of pushing every signal to everyone, the warehouse routes specific events to the people who care. A VP of Sales hire at a portfolio company goes to the operating partner focused on go-to-market. A funding announcement for a company you passed on goes to the partner who wrote the pass memo, with their own memo attached as context.
- Sourcing attribution that actually works. Most funds have strong opinions about which conferences, warm connectors, and content surfaces produce their best deal flow. Few can prove it. When deals, sources, interactions, and outcomes live in the same place, attribution becomes measurable.
- LP reporting without the fire drill. Cross-portfolio analysis that used to take weeks of manual gathering becomes a query. Revenue growth comparisons, hiring velocity across portfolio companies, sector-level performance, response to LP-specific questions about thesis exposure or geographic concentration. The quarterly reporting cycle stops eating analyst weeks.
Tools Are Commodity, Data Is the Moat
Every firm has access to the same tools. Attio, Affinity, Harmonic, PitchBook, Clay. These are available to anyone who can pay the subscription. The tools themselves are not a competitive advantage. They're table stakes.
What is a competitive advantage is what you do with the data flowing through those tools. How you connect it. How you enrich it. How you store and accumulate it over time. How you make it queryable and actionable across the entire firm.
A data warehouse built well today is more valuable in three years than it is today, because it will contain three years of trajectory data, relationship graph evolution, and institutional memory about why deals were passed and what that reasoning turned out to be worth. That accumulation can't be bought or replicated overnight.
The marginal cost advantage
The economics compound too. The first use case built on a warehouse is the most expensive. That's when the core data model, integrations, and transformation logic get established. But every subsequent use case builds on top of what already exists at a fraction of the cost and time.
Firms already experimenting with Claude skills, custom dashboards, or internal copilots discover this the hard way: each new module requires re-solving the same data problems from scratch. With a warehouse in place, every new capability starts from clean, resolved data instead of re-fighting the integration battle each time.
The competitive asymmetry isn't in the technology. It's in the head start on accumulation. The firms that wait until data infrastructure feels obviously necessary will find themselves competing against organizations that have been compounding for years.
10 Reasons to Build a Data Warehouse
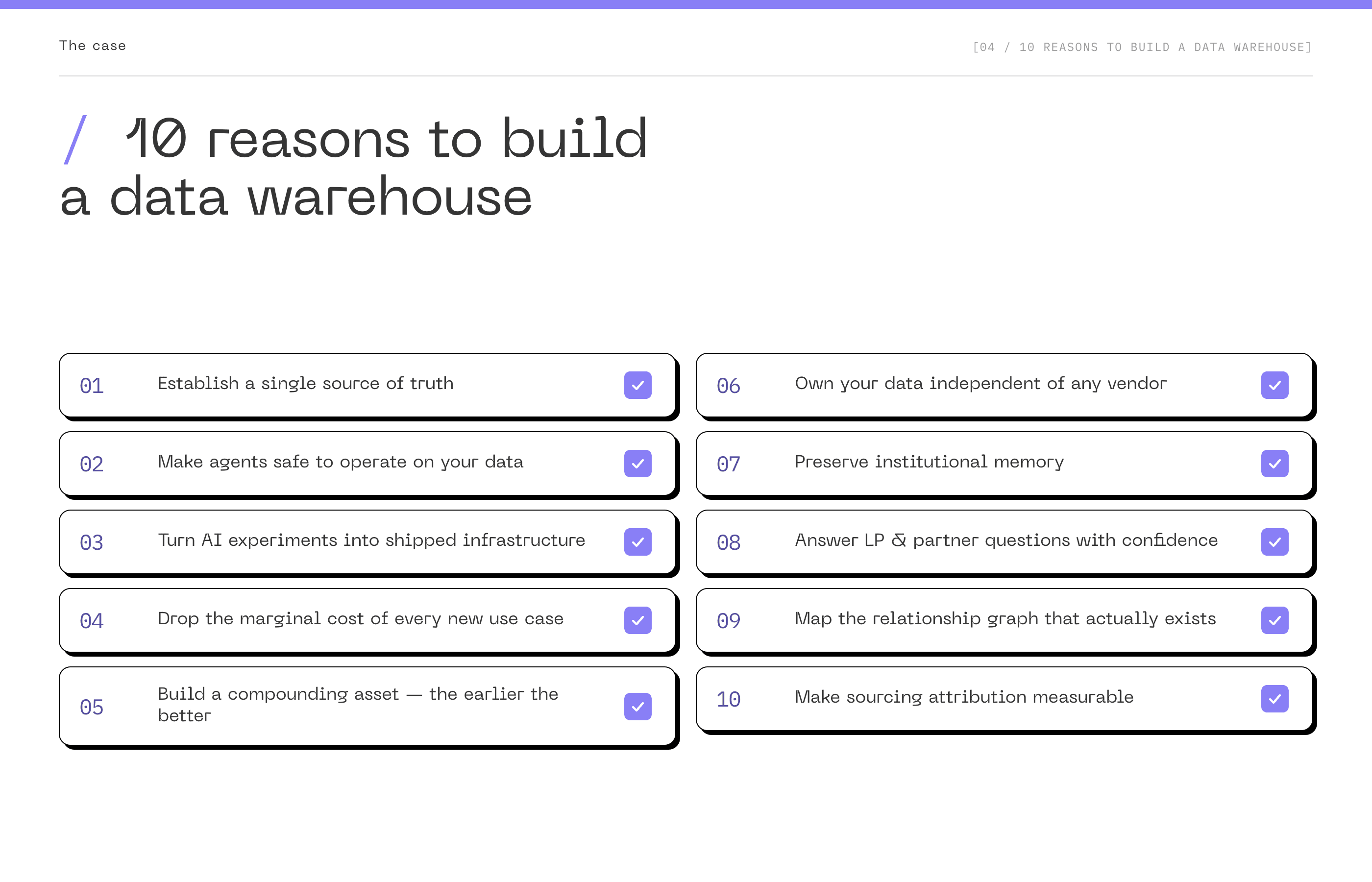
1. Establish a single source of truth. One canonical record per company, per person, per relationship. Every system, every dashboard, every agent reads from the same version. The endless debate about which spreadsheet is right disappears, because there is one answer.
2. Make agents safe to operate on your data. People can reconcile three conflicting numbers using context. Agents pick one and act on it. Entity resolution is a real data problem, not a prompt problem. The warehouse is what turns "agent-assisted workflows" from a demo into something you can actually let run overnight without checking every output.
3. Turn AI experiments into shipped infrastructure. Without a foundation, each new tool re-fights the same integration battle and most never make it past the mockup stage. With a warehouse, the gap between "interesting prototype" and "tool the team uses every Monday" collapses.
4. Drop the marginal cost and time of every new use case. The first integration is the most expensive and the slowest. Once the data model and entity resolution are in place, every new dashboard, scoring model, agent, or LP report builds on the same foundation at a fraction of the cost, and ships in days instead of weeks.
5. Build a compounding asset. The earlier the better. Static data is what you have today. A warehouse with daily snapshots gives you trajectory: how a company evolved over 18 months, how your pipeline has shifted, how your decisions have aged. Every month of delay is a month of missing snapshots that you cannot recover.
6. Own your data independent of any vendor. Your CRM, your enrichment provider, your meeting note tool, all become consumers of canonical data, not gatekeepers of it. If Affinity changes pricing or you decide to migrate to Attio, your skills, agents, and dashboards keep working.
7. Preserve institutional memory. When a senior associate leaves, the reason you passed on a company three years ago, the warm intro path to a founder, the competitive landscape notes from that sector deep dive, all retained. Firms confuse having data with having memory. The warehouse is what turns one into the other.
8. Answer the questions LPs and partners actually ask, fast and with confidence. "How many companies did we pass on in 2023 that later raised Series B from our target co-investors?" Without a warehouse, these are multi-day exercises. With a warehouse, they're SQL queries with results you can stand behind.
9. Map the relationship graph that actually exists. Most firms rely on self-reported connections. A warehouse that ingests email, calendar, and meeting data builds a relationship graph derived from real interactions. When a new founder enters the funnel, the system can surface the actual warmest path through your network.
10. Make sourcing attribution measurable. Most funds have strong opinions about which channels, events, and partners produce their best deal flow. Few can prove it. With deals, sources, interactions, and outcomes in the same queryable layer, attribution stops being a guessing game.

How to Know If You're Ready
Not every firm needs a data warehouse right now. Here's a practical readiness check.
You're probably ready if:
- Your team spends meaningful time each week stitching together info from different tools for meetings, reports, or deal review.
- Your LPs and GPs are asking questions that take hours or days instead of minutes to answer.
- You're using many tools and systems of record (CRM, Harmonic, PitchBook, Granola, Gmail, Slack, Notion) that aren't connected to each other, and the overlaps and gaps between them create real friction.
- Your team is already experimenting with Claude skills, custom dashboards, agents, or vibe-coded apps, but finding it hard to turn those experiments into scalable, reliable tools your colleagues actually use.
- You're planning to add AI capabilities or agent-driven workflows but realize the underlying data isn't structured enough to power them safely.
- You're hiring or have just hired an AI lead, data engineer, or head of platform. For technical people, a single source of truth is not optional. It's the first thing they will ask for.
- You have at least one person (internal or external) who can own the system long-term.
You're probably not ready if:
- Your team is under eight people and a well-configured CRM still covers your needs.
- You haven't agreed internally on basic definitions: what "sourced" means, what counts as a portfolio company vs. a prospect, whose relationship a deal is.
- You don't have anyone who will own the system after it's built.
- Your problem is process, not data. If your team is not using a note-taker to capture context, or keeping the CRM up to date, a warehouse can't ingest data that was never captured. (That said, this is a process problem you can solve with automations and nudges.)
Key principle. The firms that fail at this usually skip the definitional work. Before you touch any technology, your team needs to agree on what "a relationship" means, what the canonical record for a company looks like, and who owns key definitions. You cannot engineer your way out of unclear thinking.
Common Mistakes
- Over-complicating early: don't build sophisticated incremental models, complex transformations, and elaborate marts on day one. Start with basic staging models that load raw data and iterate from there.
- Not following dbt patterns: if you're using dbt, follow their best practices. Don't invent your own project structure or naming conventions. The value of dbt is that it's a standard.
- Choosing the wrong warehouse for your scale: Snowflake for a 5-person fund is overkill. Postgres for a large fund with billions of rows is inadequate. Match your tool to your scale.
- Not capturing history: if you're only storing current state, you lose the ability to analyze how things changed over time. Capture history from the start.
- Building dashboards nobody uses: don't spend weeks building elaborate dashboards until you validate that people will use them. Start with ad-hoc SQL queries. When you find yourself running the same query repeatedly, that's when to build a dashboard.
- Skipping the definitional work: the hardest part of this isn't technical, it's organizational. Whose data wins when sources conflict? What's the threshold for a record to exist? Who owns these definitions? Skip these conversations and you'll end up with a warehouse that mirrors your existing chaos instead of resolving it.
- Choosing the wrong partner to build it. A generic data engineering team can stand up Snowflake and connect Fivetran, but they don't know why PitchBook should win over Harmonic for funding data, or what questions investors actually ask of their data. Look for a partner that knows the VC tool stack, has built warehouses for funds before, and understands how investors work day to day. Industry context shortens the build, makes the schema decisions defensible, and keeps you from paying to teach someone the basics of how a fund operates.
The Bottom Line
Your firm has data. The question is whether you're going to turn it into infrastructure that compounds, or leave it scattered across tools that anyone can buy.
The case for a warehouse used to be about saving analyst time and cleaner LP reports. Both still true. The bigger case in 2026 is that the systems reading your data are changing. Agents are being asked to triage deals, draft memos, flag portfolio risk, and surface relationship paths. People can work around messy data. Agents cannot.
Connecting more sources gives you access. A warehouse gives you a data-driven fund that can be operated by agents, and a data layer that compounds in value every month it exists.
Tools are commodity. The data layer underneath them is the moat.
Loop3 Studio builds data infrastructure and internal tooling for venture capital firms. We work with investment teams to design and implement the systems, workflows, and intelligence layers that turn accumulated data into operational advantage

Written by Franco Lagomarsino
Partner At Loop3